
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
Tags
- pop()
- 파이썬
- 불리안
- 1일차
- false
- insert()
- del()
- 합집합
- 그룹 # 그룹 해체 # 단축키 #figma #Figma
- Java Script # == # === # difference # 차이
- 조건문 큰 수부터 입력받아야하는 이유
- Python
- a=1
- 부스트캠프
- 차집합
- html
- 입출력
- null # undefined
- input()
- 딥러닝
- 성적 입력받기
- 변수
- 리스트와 차이점
- 귀도 반 로섬
- 조지 불
- append()
- index()
- 변수와 입출력
- 정보를 담을 수 있는 그릇
- 변할 수 있는
Archives
- Today
- Total
I about me
Ch2. 텍스트 분류 본문

텍스트 분류
- 고객 피드백을 여러 카테고리로 분류
- 언어에 따라 고객 지원 요청 티켓을 전달 언어에 따라 그 요청을 적절한 담당자나 팀에 할당하는 과정 또는 시스템 기능
- 이메일의 스팸 필터가 받음 메일함에서 정크 메일을 걸러냄
- 텍스트의 감성분석 ex) 테슬라의 트위터 포스트 분석
- 이 장에서는 BERT에 비견하는 DistilBERT를 사용함
- DistilBERT는 BERT보다 파라미터를 줄였음에도, 성능이 꿀리지 않아 실제로 BERT를 실생활에서 이용할 때, 속도와 메모리 때문에 DistilBERT이 사용됨
1. 데이터셋 불러오기

- load_dataset() 함수로 emotion 데이터셋을 로드함
from datasets import load_dataset
emotions = load_dataset('emotion')2. Tokenizer를 활용하여 문자로 분리하기

- 부분 단어 토큰화 기법을 활용하여 Tokenization 함
- 트랜스포머는 사전 훈련된 모델에 연관된 토크나이저를 빠르게 로드하는 AutoTokenizer class를 제공함.
- from_pretrained() method를 허브 모델 ID나 로컬 파일 경로와 함께 호출하면 됨.
from transformers import AutoTokenizer
model_ckpt = "distilbert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)- tokenize 한 줄로 인코딩된 트윗을 input_ids로 반환하고, attention_mask 배열 리스트로 반환
- 배치마다 입력 시퀀스는 배치에서 가장 긴 시퀀스 길이에 맞춰 패딩
- 어텐션 마스크는 모델이 입력 텐서에서 패딩 영역을 무시하는데 사용
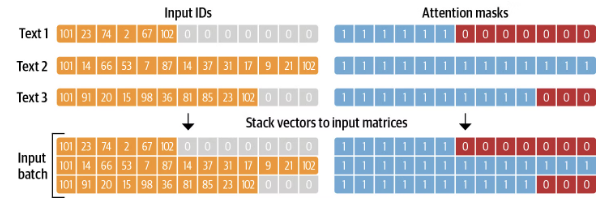
def tokenize(batch):
return tokenizer(batch["text"], padding=True, truncation=True)
emotions_encoded = emotions.map(tokenize, batched=True, batch_size=None)- 전체 emotions 데이터셋을 적용하기 위해 map()함수를 사용
- map(): 모든 샘플에 개별적으로 적용한다는 뜻
- batched=True : 트윗을 배치로 인코딩
- batch_size=None : 전체 데이터셋이 하나의 배치로 적용
emotions_encoded = emotions.map(tokenize, batched=True, batch_size=None)3-1. 트랜스포머를 특성 추출기로 사용하기

사전 학습된 트랜스포머 모델의 내부 표현(특징)을 고정된 상태로 사용하고,
이 표현을 기반으로 새로운 작업에 필요한 모델을 훈련하는 방법
자세한 코드 설명은 https://regal-forgery-1e2.notion.site/Ch2-548cef7cb1e74f21bb30372b3e6007c8?pvs=4

결과적으로 anger와 fear는 sadness와 가장 많이 혼동됨.
또 love와 surprise는 joy로 많이 오인함
분류 성능을 높이기 위해 미세튜닝하는 방법을 살펴보겠음
3-2. 트랜스포머를 미세 튜닝하여 사용하기
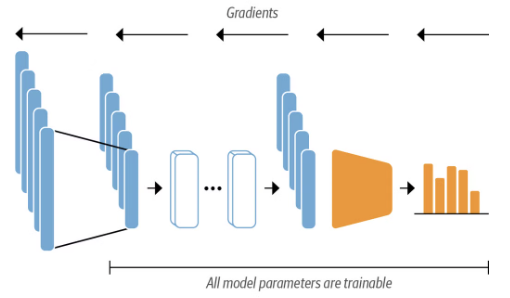
사전 학습된 트랜스포머 모델을 새로운 작업에 맞게 재학습하는 방법
이때 모델의 모든 파라미터가 조정됨
자세한 코드 설명은 https://regal-forgery-1e2.notion.site/Ch2-548cef7cb1e74f21bb30372b3e6007c8?pvs=4
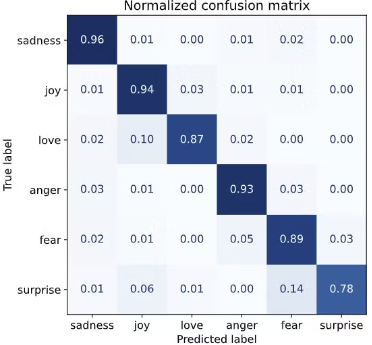
주 대각선 외에 는 거의 0에 가까워 매우 이상적인 것을 알 수 있음
'AI > NLP' 카테고리의 다른 글
| Ch1. 트랜스포머 소개 (1) | 2024.08.26 |
|---|
'AI/NLP' Related Articles
more
