
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- 파이썬
- index()
- null # undefined
- 정보를 담을 수 있는 그릇
- 변수와 입출력
- 귀도 반 로섬
- Java Script # == # === # difference # 차이
- 차집합
- insert()
- 그룹 # 그룹 해체 # 단축키 #figma #Figma
- 리스트와 차이점
- input()
- pop()
- 조지 불
- append()
- 성적 입력받기
- 변수
- a=1
- 입출력
- 부스트캠프
- 조건문 큰 수부터 입력받아야하는 이유
- 변할 수 있는
- html
- 합집합
- false
- 1일차
- 불리안
- del()
- 딥러닝
- Python
Archives
- Today
- Total
I about me
Ch1. 트랜스포머 소개 본문

인코더 & 디코더
NN
- 입력층에서 출력층까지 정보가 한 방향으로 흐름
- 중간에 있는 은닉층(hidden layer)을 통해 복잡한 패턴을 학습
RNN

- 시간적 순서를 고려한 네트워크 → 시계열 데이터
- 각 시점의 출력은 현재 입력과 이전 시점의 출력을 기반으로 계산
- h에 대한 가중치(W_h)가 t번 곱해짐에 따라
- t > 1 → ∞ (Nan, inf) → exploding → 학습이 더 이상 불가능 → clipping로 해결
- t < 1 → 0 → vanishing → LSTM, GRU로 해결
- 장기의존성 문제(the problems of long-term dependencies)
입력과 출력 사이의 거리가 멀어질수록 연관 관계가 적어지는 문제
- 장기의존성 문제(the problems of long-term dependencies)
LSTM
- RNN의 장기의존성 문제를 해결하고자 LSTM 모델 등장
- cell state를 추가하여 중요한 정보를 가중치를 더 많이 주고, 중요하지 않은 정보는 가중치를 적게 하여 성능을 올림
(자세한 내용은 나중에... 이 블로그의 중점은 '트랜스포머를 활용한 자연어처리'의 트랜스포머가 중점!) - 그러나 RNN의 고질적인 기울기 소실 문제가 완전히 없어지지는 않음
Seq2Seq (= 인코더 & 디코더)
- RNN의 1:1 대응으로 인한 번역의 어려움 문제를 해결하고자 Seq2Seq 모델 등장
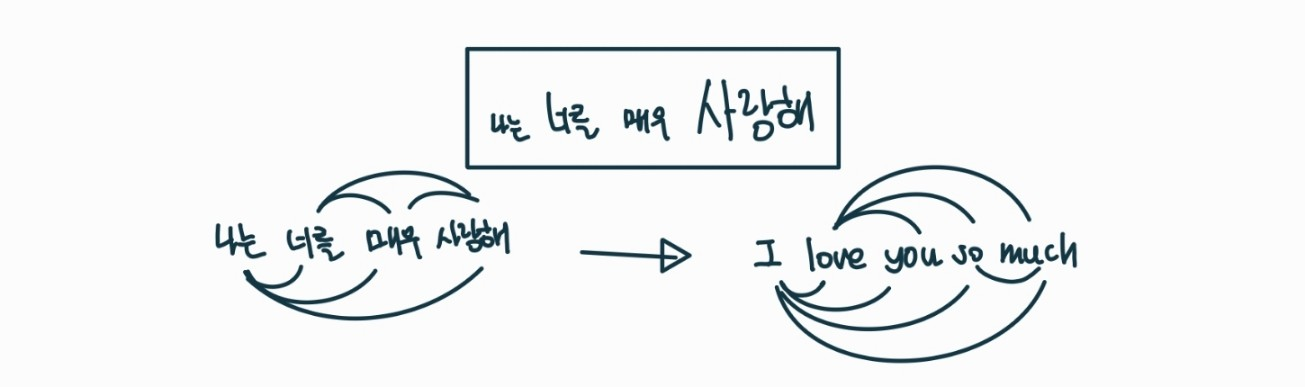
- 1:1 대응으로 인한 번역의 어려움 문제이란?
- 원래) 나는 너를 매우 사랑해 (4단어) → I love you so much (5단원)
- RNN) 나는 너를 매우 사랑해 (4단어) → I love you very (4단원) ※ 오류 ※
- How?

- 그러나 하나의 고정된 크기 벡터에 모든 정보를 압축하려고 하니까 정보 손실 발생

어텐션 매커니즘



- 어텐션 매커니즘 아이디어
- 인코더에서의 전체 입력 문장을 다시 한 번 참고함
- 단, 동일한 비율x, 해당 시점에서 예측해야할 단어와 연관이 있는 입력 단어 부분을 좀 더 집중(attention)해서 봄
- 어텐션으로 번역이 좋아졌지만, 계산이 순차적으로 진행되어 입력 시퀀스 전체에 걸쳐 병렬화 X
= 너무 각 단어에 대해서만 대응되는 느낌이라는 것
- 셀프 어텐션 매커니즘
- 순환 X
- 인코더와 디코더 각각 셀프 어텐션
NLP의 전이 학습(Transfer Learning)
전통적인 지도학습 vs. 전이학습

- 전통적인 지도학습은 각 도메인마다 별도의 모델을 학습시킴
- 전이학습은 한 도메인에서 학습된 모델의 일부를 다른 도메인에서 재사용하여 정확도가 훨씬 더 높음
ULMFiT
- 컴퓨터 비전에는 전이 학습이 많이 표준이 됐지만, NLP에서 수년 간 이루지 못하다가 몇몇 연구 단체가 전이 학습을 수행하는 새 방식을 제안했음
- 그 뒤를 이어 범용적인 프레임워크 ULMFiT가 등장함

- 사전 훈련
위키피디아 같은 소스에 있는 풍부한 텍스트를 활용하여 언어의 일반적인 패턴을 학습 - 도메인 적응
대규모 말 뭉치 → 도메인 내 말뭉치 (ex)영화 리뷰) - 미세튜닝
모델을 최종적으로 실제 작업에 맞게 조정하는 단계 (ex)영화 리뷰 감성 분류하기)
GPT
- 트랜스포머의 디코더 부분만
- ULMFiT 같은 언어 모델링 방법 사용
- BookCorps 데이터셋(어드벤처, 판타지, 로맨스 등 장르를 망라한 미출판 도서 7,000권으로 구성)으로 사전 훈련
Bert
- 트랜스포머의 인코더 부분만
- 마스크드 언어 모델링
- 영어 위키피디아로 사전 훈련
참고문헌
https://github.com/rickiepark/nlp-with-transformers
https://regal-forgery-1e2.notion.site/Ch1-ddaa3cede91e4abca99d3b511e81728a?pvs=4
'AI > NLP' 카테고리의 다른 글
| Ch2. 텍스트 분류 (0) | 2024.09.09 |
|---|
'AI/NLP' Related Articles
more
