모델이 훈련 데이터에서 예외적으로 잘 수행되었지만 테스트 데이터를 예측할 수 없는 상황을 경험한 적이 있나요?
데이터 과학 전문가들이 가장 흔히 마주치는 문제 중 하나는 과적합을 피하는 것입니다.
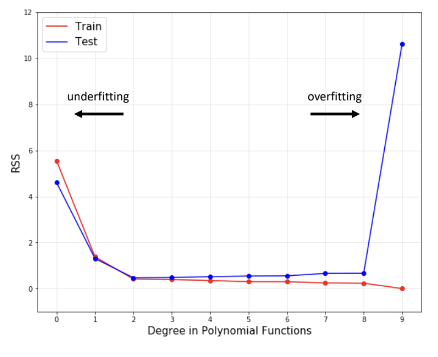
→ train data는 성능이 좋으나, test(새로운) data에 대해서는 성능이 낮다
Issue with Rich Representation
// 풍부한 표현: 모델이 매우 복잡하거나 많은 매개변수를 가지고 있어 데이터를 세밀하게 학습할 수 있는 능력
→ 근데 이렇게 좋은 것에 문제가 있을 수 있다? 그것은 바로!
input data point에서는 오류가 낮지만, 그 주변(nearby)에서는 오류가 높음 (d = 9일 때, 2에 대한 값 생각)
train 데이터에서는 오류가 낮지만, test 데이터에서는 오류가 높음
Generalization Error
Fundamental problem: we are optimizing parameters to solve
// 즉, 우리는 훈련 데이터에서 가능한 낮은 오류를 내기 위해 매개변수를 조정하는 것이 근복적인 문제 해결 방법이라며 이런식으로 최적하기 바쁩니다.
But what we really care about is loss of prediction on new data (x, y) – also called generalization error // 그러나, 우리는 새로운 데이터가 왔을 때 prediction을 잘하는 것이 중요합니다. 이를 일반화 오류라고 합니다.
Divide data into training set, and validation (testing) set // 그래서 우리는 데이터를 훈련 세트와 검증(테스트) 세트로 나누어야 합니다.
Regularization (Shrinkage Methods)
// 정규화
많은 특징을 사용할 경우, 예측 함수가 매우 표현력이 높아집니다.(모델 복잡성 증가) 그러므로
덜 표현력이 높은 함수를 선택한다. (ex) 낮은 차수의 다항식, 더 적은 RBF 중심, 더 큰 RBF 대여폭) ?RBF: 입력 데이터의 거리에 따라 값을 반환하는 함수
매개변수의 크기를 작게 유지한다. - 정규화(Shrinkage): 큰 매개변수 θ에 페널티를 부여하여 매개변수 값을 축소 - λ: 정규화 매개변수로, 낮은 손실과 작은 θ 값 사이의 균형을 맞추기 - λ 값 ↑ , 정규화 효과가 강화되어 모델의 복잡성이 줄어듦
Different Regularization Techniques
= 아예 훈련 데이터의 크기를 완전 늘려 다양한 패턴을 학습시켜 Overfitting을 줄이는 방법
Big data
Data augmentation (데이터 증강)
Early stopping (조기 종료) // 검증 데이터에서의 성능이 나빠지는 것을 관찰하면 훈련을 즉시 중단하는 기법