
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | |||||
| 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 10 | 11 | 12 | 13 | 14 | 15 | 16 |
| 17 | 18 | 19 | 20 | 21 | 22 | 23 |
| 24 | 25 | 26 | 27 | 28 | 29 | 30 |
| 31 |
Tags
- input()
- index()
- 입출력
- Java Script # == # === # difference # 차이
- 차집합
- 조지 불
- null # undefined
- a=1
- 귀도 반 로섬
- pop()
- 합집합
- 변할 수 있는
- 불리안
- 리스트와 차이점
- langchain
- 성적 입력받기
- 조건문 큰 수부터 입력받아야하는 이유
- insert()
- 변수
- 파이썬
- prompt
- 정보를 담을 수 있는 그릇
- 부스트캠프
- 딥러닝
- html
- append()
- Python
- del()
- 그룹 # 그룹 해체 # 단축키 #figma #Figma
- 변수와 입출력
Archives
- Today
- Total
I about me
[강의노트 5] Learning rate 본문
Improve your training error
# Learning rate
# Learning rate decay
# Optimal Learning Rate for Different Batch sizes
Learning rate
모델이 데이터를 학습하며 가중치를 조정해나간다.
그래서 학습의 일정 기간동안, 가중치의 크기를 조절하여 손실을 줄이는 방향으로 학습한다.
이때, 학습률이 높으면 가중치가 크게 변하고, 낮으면 작게 변합니다.
즉, 학습률은 잠깐 뜸들여 방향을 찾는 것을 말한다.

- 손실이 급격히 증가하다는 것 = very high 학습률
- 손실이 처음에는 감소하다가 나중에 평평 = 아직은 high 학습률
- loss가 확 줄어드는 방향으로 간다? → good 학습률
- loss이 매우 천천히다? → low 학습률
Learning rate decay
: 처음에 학습률을 높게 설정하고 학습이 진행될수록 점점 낮추는 것을 말함
- Step Decay
- 일정한 에포크마다 학습률을 일정 비율로 줄이는 방법
- 예를 들어, Resnet 30, 60, 90 에포크마다 학습률을 0.1배로 감소시킵니다.
- 초기 학습률이 0.1이라면, 30번째 에포크에서 학습률은 0.01, 60번째 에포크에서 0.001, 90번째 에포크에서 0.0001이 됨

- 초기 학습률이 0.1이라면, 30번째 에포크에서 학습률은 0.01, 60번째 에포크에서 0.001, 90번째 에포크에서 0.0001이 됨
- Cosine Decay/ Linear Decay/ Inverse sqrt
- 학습률을 코사인/ 선형/ 역제곱근(1/sqrt()) 함수의 형태로 줄이는 방법



- Linear warmup
- 결국 너 이놈이 무슨 짓을 해도 좋구나...! 제일 좋다

Optimal Learning Rate for Different Batch sizes
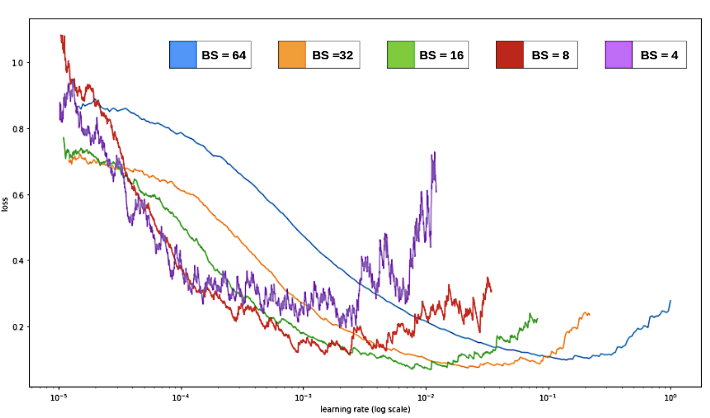
- 일반적으로 배치 크기가 클수록 노이즈가 적어지고 더 부드러운 그래프를 생성하는 경향이 있다.
- 더 큰 배치 크기에서는 더 높은 학습률이 최적일 수 있고, 작은 배치 크기에서는 더 작은 학습률이 더 적합하다.
- 배치 큰 경우(파란색), loss가 최소가 되는 지점이 학습률이 높은 곳
- 배치 작은 경우(보라색), loss 가 최소가 되는 지점이 학습률이 낮은 곳

| **Large Batch | Small Batch |
| - Accurate estimate of the gradient (정확한 기울기 추정) - High computation cost per iteration (반복당 높은 계산 비용) - High availability of parallelism (높은 병렬 처리 가능성) 많이 할수록 노이즈가 더 적어지고 더 부드러운 그래프이다. |
- Noisy estimate of the gradient (잡음이 많은 기울기 추정) - Low computation cost per iteration (반복당 낮은 계산 비용) - Low availability of parallelism (낮은 병렬 처리 가능성) 적게씩 하니까 정확도가 올라간다. |
'AI > Lecture note' 카테고리의 다른 글
| [강의노트 5] Bias-Variance Tradeoff (0) | 2024.06.13 |
|---|---|
| [강의노트 2] Activation Function (0) | 2024.06.13 |
| Contents (0) | 2024.03.27 |
'AI/Lecture note' Related Articles
more

